Introduction To OOP: Objects
Published on March 6, 2024 and updated on March 13, 2024

Undoubtedly, two of the most known programming paradigms are object-oriented programming and functional programming. We can debate all day about the best paradigm, but one thing is clear: they all have pros and cons. I can confidently say that FP and OOP are here to stay for now. So, as a software engineer, getting to grasp FP or OOP concepts is very important, so in this blog post, we will look over one key aspect of object-oriented programming: Objects and Classes.
What is an Object in OOP?
Objects are the building blocks of an OO program. A program that uses OO technology is a collection of objects.
Object-oriented programming encourages combining our data, functions, or methods in a single object. Unlike some programming paradigms, such as procedural programming, where we write functions to mutate the global scope of data that is probably living elsewhere, OOP encourages us to put our data into a single entity called an object and to write methods or functions that work on these data inside our object.
In its basic form, an object can be defined by two major components: attributes and behaviors. And it can represent real-life entities. For example, we can say that a person is an object.
A person has attributes like eye color, age, height, mouth, legs, etc. A person also has behaviors like walking, talking, breathing, etc. As said earlier, an object is an entity that contains both attributes and behavior. Based on this, we can confidently say that a person's behavior works on the attributes of a person. For example, a person's walking behavior will work on the attribute of the legs because the leg does the job of walking.
Programmatically, we can say that the attribute of a person is also known as the concrete data about the person, and the person's behavior is also known as the person's methods programmatically.
Therefore, we can say that a person's eye color, age, and height are the data of the person's object. And walking, talking, and breathing are the methods or behaviors of the person's object.
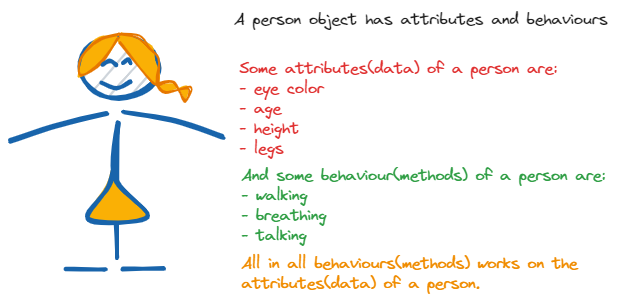
A person object has attributes(data) and behaviours(methods)
Object data
The data stored within an object represents the state of the object. In OO programming terminology, this data is called attributes.
We can create an employee object and give it attributes such as Social Security numbers, date of birth, gender, phone number, etc. The below example shows an object with the mentioned data or attributes.
Employee.java
public class Employee {
private String name;
private String socialSecurityNumber;
private String dateOfBirth;
private String phoneNumber;
}Object Behaviours
The behavior of an object represents what the object can do. In procedural languages, the behavior is defined by procedures, functions, and subroutines. In OO programming terminology, these behaviors are contained in methods, and you invoke a method by sending a message to it. In our employee example, consider that one of the behaviors required of an employee object is to set and return the values of the various attributes. Thus, each attribute would have corresponding methods, such as setGender() and getGender(). In this case, when another object needs this information, it can send a message to an employee object and ask it what its gender is. The below example shows how these methods work.
Employee.java
package com.example.chapter_one;
public class Employee {
...
public void setSocialSecurityNumber(String socialSecurityNumber) {
this.socialSecurityNumber = socialSecurityNumber;
}
public String getSocialSecurityNumber() {
return socialSecurityNumber;
}
}Getters and Setters - The concept of getters and setters supports the concept of data hiding. Because other objects should not directly manipulate data within another object, the getters and setters provide controlled access to an object's data. Getters and setters are sometimes called accessor methods and mutator methods, respectively.
So, let's say we have an Payroll object that contains a method called CalculatePay() that calculates the pay for a specific employee. Among other information, the Payroll object must obtain the Social Security number of this employee. To get this information, the payroll object must send a message to the Employee object (in this case, the getSocialSecurityNumber() method). This means that the Payroll object calls the getSocialSecurityNumber() method of the Employee object. The employee object recognizes the message and returns the requested information.
The diagram below is a class diagram representing the Employee/Payroll system we have been talking about. In the next blog post, we will talk more about classes, so stay tuned.

A UML diagram of the employee object and the payroll object
Each class/object diagram is defined by three separate sections: the name itself, the data (attributes), and the behaviors (methods). For example, the Employee class/object diagram's attribute section contains SocialSecurityNumber, Gender, and dateOfBirth, whereas the method section contains the methods that operate on these attributes.
When an object is created, we say that the objects are instantiated. Thus, if we create three employees, we create three distinct instances of an Employee class. Each object contains its copy of the attributes and methods.
An Implementation Issue - Be aware that there is not necessarily a physical copy of each method for each object. Rather, each object points to the same implementation. However, this is an issue left up to the compiler/operating platform. From a conceptual level, you can think of objects as being wholly independent and having their own attributes and methods.
Why objects?
In structured or procedural programming, the data is often separated from the procedures(), and often, the data is global, so it is easy to modify data that is outside the scope of your code. This means that access to data is uncontrolled and unpredictable (that is, multiple functions may have access to the global data). Second, because you have no control over who has access to the data, testing and debugging are much more difficult. Objects address these problems by combining data and behavior into one complete package.
So this means that an object can contain entities such as integers and strings, which are used to represent attributes. They also have methods that represent behaviors.
In an object, methods are used to perform operations on the data and other actions. Perhaps more importantly, you can control access to members of an object (both attributes and methods). This means some members, attributes, and methods can be hidden from other objects. For instance, an object called Math might contain two integers called myInt1 and myInt2. Most likely, the Math object also includes the necessary methods to set and retrieve the values of myInt1 and myInt2. It might also have a method called sum() to add the two integers together. Don't worry about the code; we will talk about classes in a different post.
Math.java
public class Math {
// Here, myInt1 and myInt2 are attributes of the Math object. They are private, meaning they are hidden from other objects.
private int myInt1 = 1;
private int myInt2 = 2;
// This is a method called sum(). It performs an operation on the data (myInt1 and myInt2) by adding them together.
int sum() {
return myInt1 + myInt2;
}
// These are methods used to set the values of myInt1 and myInt2. They control access to these attributes.
public void setInt1(int myIntOne) {
myInt1 = myIntOne;
}
public void setInt2(int myIntTwo) {
myInt2 = myIntTwo;
}
// These are methods used to retrieve the values of myInt1 and myInt2. They also control access to these attributes.
public int getInt1() {
return myInt1;
}
public int getInt2() {
return myInt2;
}
}So basically, if we did not add the getters and setters methods, myInt1 and myInt2 will never or cannot be accessed from any place in our code (because they are private attributes/data) except inside the class in which it was declared.
Data Hiding - In OO terminology, data are referred to as attributes and behaviors as methods. Restricting access to certain attributes and/or methods is called data hiding.
Encapsulation
This brings us to our last sub-topic on objects, encapsulation. Encapsulation is the principle that binds together the data and functions that manipulate the data and that keeps both safe from outside interference and misuse. The data of an object is known as its attributes, and the functions/methods that can be performed on that data are known as methods.
By using encapsulation, thus combining the data and the methods, we can control access to the data in the Math object. By defining these integers as off-limits, another logically unconnected function cannot manipulate the integers myInt1 and myInt2 — only the Math object can do that.
- Sound Class Design Guidelines - Remember that it is possible to create poorly designed OO classes that do not restrict access to class attributes. The bottom line is that you can design bad code just as efficiently with OO design as with any other programming methodology. Take care to adhere to sound class design guidelines.
In general, objects should not manipulate the internal data of other objects (that is, myObject which is an instance of the Math object should not directly change the value of myInt1 and myInt2 ). It is usually better to build tiny objects with specific tasks rather than large objects that perform many tasks.
Conclusion
So, we now know what an object is in OOP: a combination of data/attributes and methods/behaviors in a single entity. We cannot talk about objects without talking about classes, so in the next blog post, we will be demystifying classes in OOP. Stay tuned. Here is the link to the next blog post about Classes in OOP.
I am reading a book called Object-Oriented Thought Process(not an affiliate link), which inspired this blog post. I am also writing some notes down as I read; if it is something you like, check out this GitHub repo for my notes on OOP, and don't forget to also star and share the repo with your friends.
Hey 👋, I believe you enjoyed this article and learned something new and valuable. If you are into NextJS, check out if NextJS is using unreleased React features over here. You can also follow me on Twitter (or instead X 😂) as I share more tips and tricks to make you improve as a better software engineer.
Happy Coding!